
Actualmente la gobernanza de los centros de datos ha evolucionado hacia un control y automatización qué, por primera vez, se establece en la metodología de operaciones. Las posibilidades de migración de las cargas de computo no ya sólo entre servidores (virtualización) sino entre distintos escenarios (onpremise to cloud, cloud to onpremise, P2V, etc…) han generado una complejidad a la hora de tomar decisiones en cuanto a la estrategia y por lo tanto una mayor dispersión en el cálculo del TCO total de las plataformas.
No cabe duda que la mayoría de profesionales de TI han cambiado su discurso en lo relacionado al diseño y arquitectura de estas plataformas. Aparecen términos como hibridación, elementos propios de la intregración continua y sobre todo un uso del concepto, cada vez mas extendido, del coste por uso de los diferentes sistemas que intervienen.
Sin embargo, las premisas relativas a la continuidad de negocio (backups, contingencia, etc.) parecen inalterables. En la mayoría de las ocasiones seguimos anclados en un elemento básico de arquitectura: El cluster Activo/Pasivo y, como mucho, se han sustituido elementos (repositorios, librerías de cinta, etc.) por elementos propio de la nube, así hablamos de hacer los backups en espacios de almacenamiento S3, Glacier, o de subir réplicas de los servicios en instancias EC2 (usando terminología de AWS). Todo esto no es más que la sustitución de elementos por otros de nuevo cuño, posiblemente más rentables, pero que poco aportan tanto al funcionamiento como a los nuevos conceptos.
Cluster Activo – Pasivo
Aunque todos lo conocemos no viene mal recordar su uso. Básicamente consiste en un sistema que se replica asíncronamente y en una sola dirección. Es decir «copiamos» nuestros datos en otra ubicación de manera periódica para, en caso de fallo, levantar los servicios críticos en la ubicación donde hemos. Es la manera más tradicional y quizás la menos rentable económicamente de mantener un sistema de contingencia.
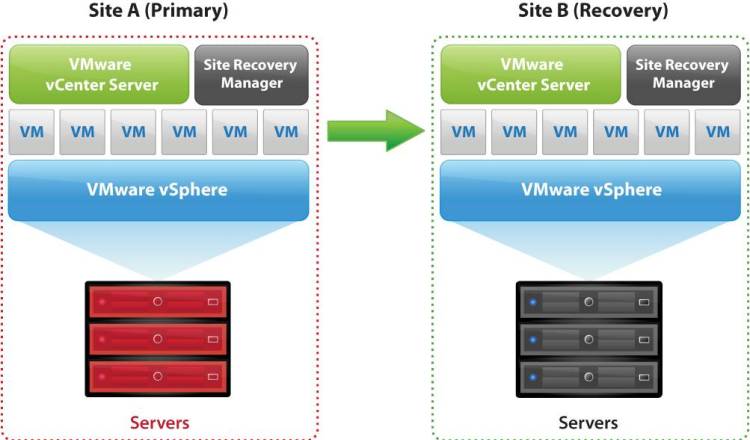
CPDs Activo / Pasivo con VMware
Los problemas que nos genera este modelo:
- Duplicación de la infraestructura (al menos en parte). Necesitaremos almacenamiento, servidores, switches… Prácticamente hacemos una réplica a menor escala del CPD de producción, para tenerlo apagado el 99% del tiempo. En muchas ocasiones se utiliza hardware retirado u obsoleto, lo que aumenta exponencialmente la incertidumbre ante el éxito de la operación de levantar los servicios en contingencia.
- Versionado de licenciamento. Además del hardware se duplican licencias y genera problemas en mantener en ambos CPDs compatibilidad plena para asegurar el servicio
- Complejidad en las pruebas de recuperación del servicio. En la mayoría de ocasiones debemos levantar el entorno de contingencia en real para probar su estado y la del servicio de recuperación así como comprobar que nuestras políticas de RPO/RTO se cumplen.
- Tiempos de recuperación del servicio largos, derivados en muchas ocasiones de la falta de automatización.
- Vuelta atrás complicada. Una vez superada la contingencia resincronizar en sentido contrario los servicios no suele ser una tarea fácil y genera más de un quebradero de cabeza y, lo que es peor, parada de los servicios.
Y si, hemos echo una descripción catastrófista de la solución apuntando sus problemas, pero no ha sido en balde sino que hila el discurso hacia un modelo con mejores resultados en los que se aprovechan recursos y por tanto rentabilizamos la inversión. Se trata de la evolución hacia CPDs Activo / Activo que procuran un nuevo nivel de servicios.
Cluster Activo / Activo
Cómo comentábamos anteriormente, los escenarios en los departamentos de TI han cambiado. Un cluster activo activo y más en su versión «Metro Cluster» (ubicaciones remotas) era algo al alcance de no todos los presupuestos de TI de las empresas. Por fortuna en el mercado encontramos soluciones asequibles, hasta tal punto que, en el caso de PURE STORAGE se encuentran incluidas en licenciamiento base del equipamiento: basta tener dos cabinas para contar con todo lo necesario para activar un cluster activo / activo. El detalle de la solución Active Cluster de Pure Storage se puede ver públicamente en su web con números vídeos y explicaciones pero haremos una descripción básica de su funcionamiento.
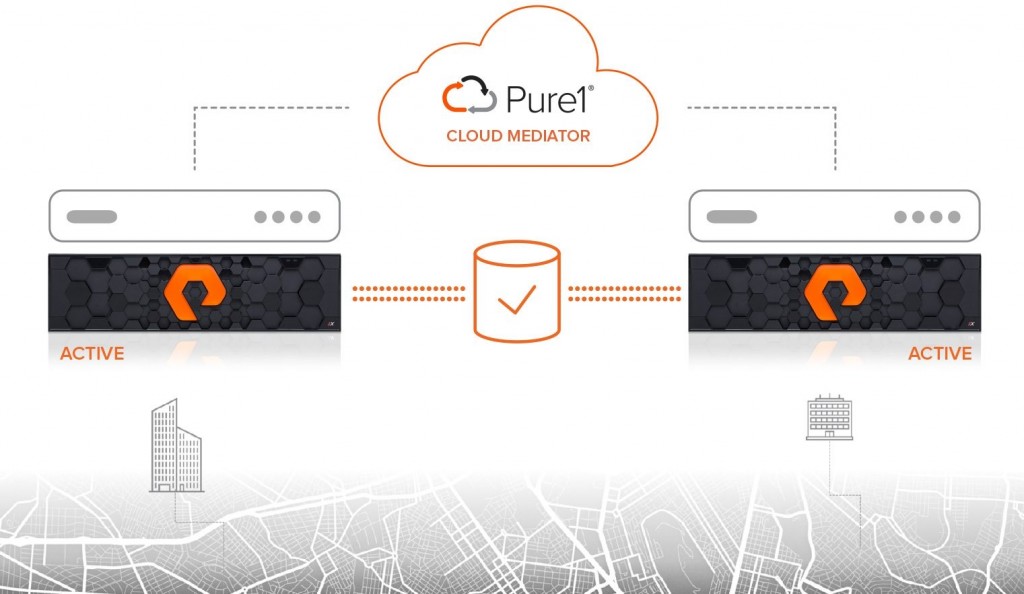
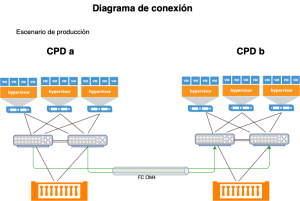
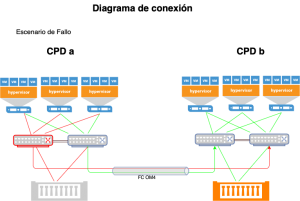
Básicamente consiste en dos cabinas que se sincronizan en modo síncrono y tiempo real y un orquestador Pure1 Cloud Mediator, que se encarga de gestionar tanto la dirección del sincronismo cómo el estado de las cabinas, automatizando totalmente todo el tráfico (incluida vuelta atrás) de los distintos volúmenes. Este servicio se encuentra alojado en la nube por lo que no es necesario destinar recursos on-premise para la orquestación del cluster.
De esta manera y con una conexión multipath. Todos los servicios tienen acceso a los datos en cualquier circunstancia.
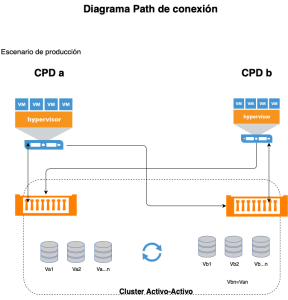 |
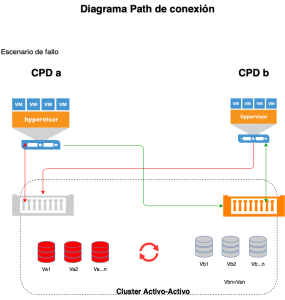 |
 |
 |
Qué nos permite este este modelo:
- En primer lugar ya no estaríamos hablando de un CPD de contingencia: hemos pasado a un CPD ampliado donde las máquinas y servicios que antes permanecían apagados, ahora se añaden como recursos disponibles para producción, entornos de desarrollo etc… y todo ello conservando la capacidad de contingencia.
- Mejor distribución de las cargas de trabajo al contar con más recursos disponibles.
- Optimización del coste del mantenimiento (hard y soft) al tener en modo activo todos los recursos.
- Vuelta atrás de los datos automatizado y transparente al usuario, sin cortes de servicio.
- Pero sobre todo, y quizá esta sea la cualidad más sobresaliente, tiempos de RPO/RTO cercanos a cero.
Hibridando el modelo
Hasta aquí estábamos en un entorno físico, normalmente en nuestras instalaciones ya sea en una o varias localizaciones geográficas. Indudablemente hablar de cambio de concepto en TI y no fijarse en los escenarios cloud sería quedarse a medio camino entre las posibilidades de mejora en la optimización de las arquitecturas de los centros de datos. Además, en estos entornos es donde los conceptos IaaS y PaaS cobran su verdadera dimensión y dónde, con las mediciones adecuadas, podemos sacar partido de entornos de pago por uso haciendo nuestra infraestructura de servicios más solida y disponible.
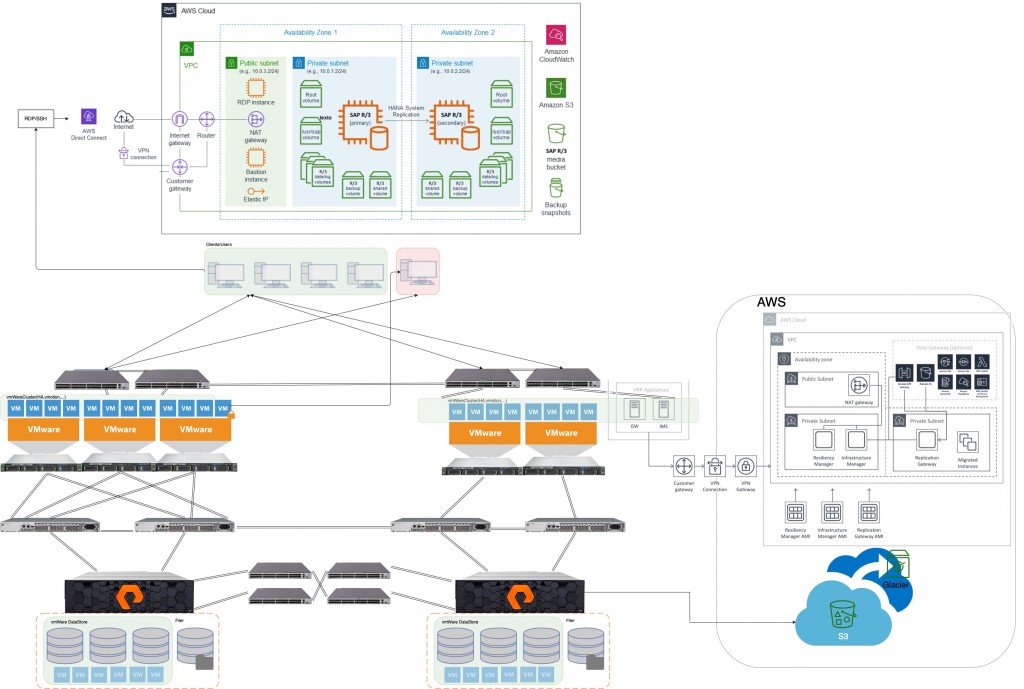
Diagrama completo de CPD híbrido (supuesto para el ejemplo)
En la figura de arriba, como ayuda a la explicación, hemos representado algunas de las posibilidades de hibridación para montar sistemas de continuidad de negocio, Disaster Recovery o simplemente alta disponibilidad en entornos de CPDs ampliados.
En el diagrama hemos separado 3 entornos, qué como piezas de un puzzle, podemos ir añadiendo o eliminando en función de nuestras necesidades.
- Entorno On-premise. Basado en un Active Cluster de Pure Storage
- Entorno Cloud Activo. Es el que representamos en la parte superior de la imagen en un supuesto para SAP R/3 pero escalable a otros servicios. Básicamente podríamos utilizar dos tipos de tecnología:
- Cloud Block Store que nos permite tener una cabina alojada en AWS con espacio ajustado a nuestra necesidades y el mismo sistema operativo que el nuestras cabinas on-premise. Esto se traduce en sincronización nativa, migración de cargas sencilla y en ambas direcciones on-premise to Cloud, Cloud to on-premise e incluso el movimiento y sincronismo entre diferentes zonas de disponibilidad. Con esta tecnología tendríamos una réplica de todos nuestros datos en AWS disponible para levantar servicios desde instancias de EC2 de manera segura y rápida.
- Otra posibilidad es utilizar CloudSnap. Con esta tecnología podemos almacenar en AWS S3 IA (almacenamiento barato) gran cantidad de Snapshots de nuestras volúmenes, e incluso a nivel de VM, con la posibilidad de rehidratar los snapshots directamente en instancias EC2 o en un nuevo entorno on-premise. Es un escenario ideal para contingencia en el concepto tradicional, pero también para retención o Disaster Recovery ya que consigue, con un coste ínfimo un entorno de recuperación tanto de servicios como de datos muy seguro.
- Por último en el entorno VRP, proponemos en el diagrama un entorno creado con herramientas Legacy. En este caso utilizamos Veritas Resiliency Platform cómo método para la réplica de datos y orquestación de los servicios. En este caso es el software de Veritas el que ese encarga de del sincronismo de los datos, vigilancia de la disponibilidad de los servicios y aplicación de las políticas de RPO definidas en la propia herramienta y que permitirá hacer «ensayos» de contingencia sin afectar al entorno de producción así como unos tiempos de recuperación muy cortos y, además, todo ello de forma completamente automatizada
Dependiendo del tamaño, número de servicios, y tiempos de RPO podemos ir «jugando» con estos entornos de forma complementaria o sustitutiva. Cada caso requiere un estudio pormenorizado de la situación para poder adaptar la solución a las necesidades, tanto de servicio como presupuestarias.
¿Por qué la referencia a DevOps?
La gestión de entornos tan diversificados en que se imbrican conceptos y tecnologías propias del CPD tradicional y de los servicios Cloud requieren una nueva manera de abordar su gobernanza.
La cultura DevOps es, quizá, la manera mas efectiva de agilizar, automatizar y garantizar los servicios, su disponibilidad y la calidad de la prestación de los mismos.
En concreto en el escenario 2 que describíamos en el apartado anterior las API_Rest de Pure permiten la integración y uso de ANSIBLE y herramientas similares para el despliegue automatizado de servicios. Estas herramientas permiten combinarse con otras mas cercanas al entorno cloud como Terraform que nos permitirían realizar la puesta servicio de instancias EC2 a partir de los snapshots de Pure de manera totalmente orquestada y automatizada. Por tanto la implementación de procesos y flujos de la plataforma pasan a formar parte de la estrategia de PaaS o IaaS del equipo DevOps.
No nos gustaría acabar sin dar un repaso a las herramientas más interesantes en este área y qué, en combinación con las tecnologías propuestas permiten alcanzar nuevos objetivos en cuanto a rentabilidad de nuestros sistemas de continuidad de negocio.
Algunas de nuestras favoritas son:
- Ansible. Fácil y sencilla herramienta para aprovisionamiento, despliegue y orquestación.
- Docker. Inevitable en entornos híbridos y que permite agilizar y simplificar la distribución de aplicaciones en entornos muy escalables.
- Kubernetes. Y si usamos contenedores, Kubernetes se hace imprescindible para migraciones a la nube, sobre todo si tenemos un entorno multicloud, y en general para la administración y control de sistemas distribuidos en ambientes de ejecución heterogéneos.
- Icinga. Como evolución de Nagios, seguramente la herramienta en entornos DevOps más conocida para la monitorización de cualquier infraestructura que además permite identificar tendencias e integrase casi con cualquier cosa.
- Puppet. Similar en el próposito a Ansible permite automatizar la gestión de infraestructura para despliegues rápidos.
- Raygun. Que proviene del mundo software permite monitorizar y registrar errores tanto en aplicaciones como en plataformas y reportar hasta la primera línea de código/función/API en que se da el fallo.
- Terraform. Nacida nítidamente como herramienta de infrastructure as code y perfectamente integrada con AWS y otras nubes públicas permite reproducir la infraestructura en entornos multicloud.
Conclusiones
El nuevo escenario que se dibuja en la gestión de los CPDs nos trae un buen puñado de conceptos e «ingredientes» nuevos que debemos combinar buscando eficiencia y rentabilidad, pero también sencillez en su gestión.
No tiene sentido ya inversiones de muchos miles de euros para mantenerlos apagados y aparcados en racks que consumen recursos (comunicaciones, refrigeración, etc…). Menos aún si no tenemos la certeza de que vamos a poder usarlo en cualquier momento.
Parece lógico eliminar el concepto de contingencia tal y como lo conocemos y migrar hacia CPDs ampliados, ya sea esta extensión on-premise o en la nube.
La complejidad de opciones requiere un cuidado estudio de oportunidades y valorar tanto operativamente como económicamente la solución idónea.


